傳統校勘流程向數字化平臺遷移的初步探索
——以中華書局點校本《三國志》的修訂爲例
鳳凰出版社 吳葆勤
正是基于對不同校勘層次的理解,從collation到criticism的傳統校勘流程向數字化平臺遷移,我們有了三點思考:一是collation的半自動化完全可以通過技術手段實現,這當然要以古籍版本的全文數字化爲前提;二是criticism所需要參考的各類學術文獻,完全可以通過數字化平臺彙聚,並有無限拓展的空間;三是“定是非”的核心工作,任何技術手段只能輔助而不能取代,必須完全依靠研究者自身的學識,這也正是學者永恒的價值所在。
1970年,E. F. Codd發表了里程碑式的論文A relational model for large shared data banks,提出了關係型數據庫理論和結構化查詢語言SQL(Structured Query Language)。從此,數據庫應用進入了學術研究的視野。目前的數字文獻大致分爲傳統平面媒體文獻的數字影像、數字編碼的全文文本以及結構化的數據庫。拋去計算機科學的術語,直白地說,數據庫中的表格(table)就是裝載不同類型數據(data)的容器,SQL語言則是數據庫提供的操作數據的工具。數據庫的規範、實用性,爲校勘流程的數字化提供了可能。
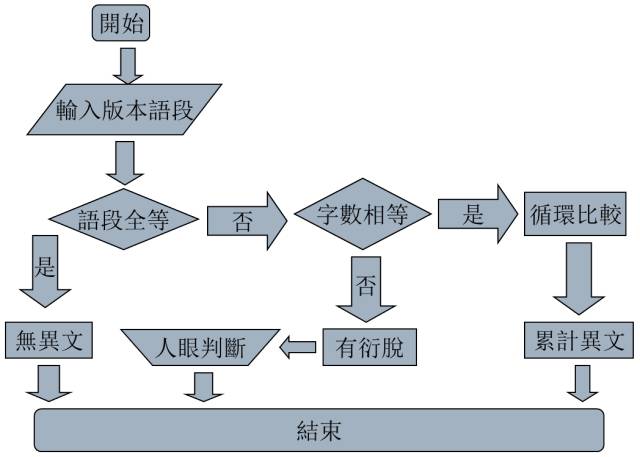
我們在數據庫中設計表格,把校勘所需要的文本數據(text)裝載進去,包括:(1)版本數據,指同一種古籍多個不同版本的電子文本,這是對校法必備的基礎數據;(2)參考數據,指與校勘相關的研究文獻,以及他校法的來源典籍等等,參考數據的採集是開放的、可持續的;(3)校勘成果,這是以前兩項數據爲基礎,綜合運用不同的校勘方法後,寫入數據庫的新內容,包括校勘資料長編、底本處理意見、校勘記以及統計數據等。我們利用SQL語言,編寫不同的函數(function)和視圖(view),對“版本數據”進行對校,辨别異同;對“參考數據”進行彙總,作爲校勘依據;利用SQL書寫查詢(query)代碼的自由度,對“版本數據”窮盡式地檢索,這又是本校法的靈活運用。下面我就以中華書局點校本《三國志》的修訂作爲實例,向各位專家彙報。不當之處,懇請批評指正。
 《三國志》古籍版本書影
《三國志》古籍版本書影1959年,中華書局點校本《三國志》問世。1982年,點校本作了較大幅度的挖改,推出第二版,重印期間又修正個别文字。點校本在海內外成爲最權威的版本,今天的各類整理本、注譯本,無一不受其影響。然而半個世紀以來,新資料、新方法、新成果不斷涌現,點校本二十四史的全面修訂已經勢在必行,《三國志》自然也不例外。早在2002年,我的父親——復旦大學古籍所吳金華教授就計劃全面修訂點校本《三國志》;2007年,修訂計劃作爲中華書局“二十四史”及《清史稿》修訂工程的子項目立項,成立了修訂組,做了大量的資料積累、專題研究工作,並形成較爲完整的《修訂長編》。2013年,父親去世,承蒙中華書局的信任,讓我來繼續完成修訂任務。從那時候起,我就一直思考三個問題:一是修訂組成員分散在各地,怎樣才能在同一個平臺下,遵循統一的修訂標準,高質量地完成修訂任務?二是除了已有的《修訂長編》需要覆核,不斷公布的新材料還需要納入到研究視野中,怎樣才能既减少重複勞動,又能兼顧到新材料的兼容,從而保證修訂本以全新的面貌問世?三是古籍整理永遠有不斷推陳出新的歷史要求,一個階段工作的終點,必然又是下一個階段工作的起點,怎樣才能預留出未來修訂的拓展空間,而不是奢望畢其功于一役?經過時斷時續的探索、徬徨與實踐,結合自己的研究經驗和知識儲備,我試圖利用數據庫來解決上述問題。
(一)數據庫設計
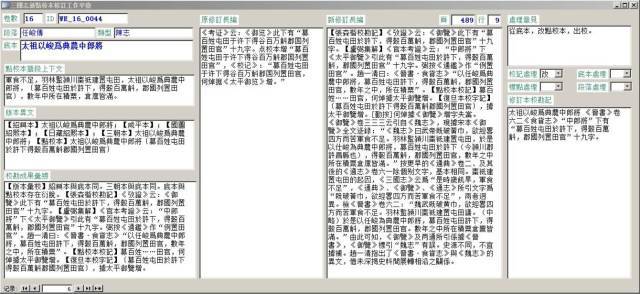
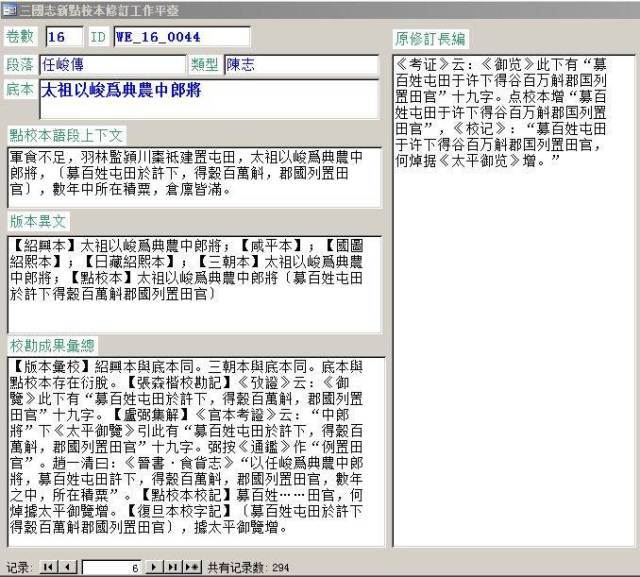
點校本《三國志》修訂的主要任務是以百衲本爲底本、以傳世宋元本爲通校本,充分吸收前人重要研究成果,在原點校本的基礎上,形成新的修訂本。修訂稿由三部分構成,一是在原《修訂長編》基礎上增補校正而成新《修訂資料長編》,二是據新《長編》提出針對底本的處理意見,三是增訂原點校本的校勘記。新《長編》是處理意見和校勘記的基礎,要盡可能完備。根據這個需求,數據庫表結構中各要素間的關係,用公式表示如下:
[中華書局點校本] [nvarchar](50) NULL,
[段落] [nvarchar](50) NULL,
[類型] [nvarchar](50) NULL,
[卷數] [char](2) NULL,
[頁] [int] NULL,
[行] [int] NULL,
(2)版本語段
[百衲本] [nvarchar](50) NULL,
[紹興本] [nvarchar](50) NULL,
[國圖紹熙本] [nvarchar](50) NULL,
[日藏紹熙本] [nvarchar](50) NULL,
[咸平本] [nvarchar](50) NULL,
[三朝本] [nvarchar](50) NULL,
[南監本] [nvarchar](50) NULL,
……
(3)校勘資料
[張森楷校勘記] [nvarchar](max) NULL,
[百衲本校勘記] [nvarchar](max) NULL,
[盧弼集解] [nvarchar](max) NULL,
[點校本校記] [nvarchar](max) NULL,
[復旦本校字記] [nvarchar](max) NULL,
[原修訂長編] [nvarchar](max) NULL,
……
(4)修訂成果
[新修訂長編] [nvarchar](max) NULL,
[處理意見] [nvarchar](max) NULL,
[修訂本校勘記] [nvarchar](max) NULL,
(5)統計數據
[校記處理] [nvarchar](10) NULL,
[文字處理] [nvarchar](10) NULL,
[標點處理] [nvarchar](10) NULL,
[段落處理] [nvarchar](10) NULL,

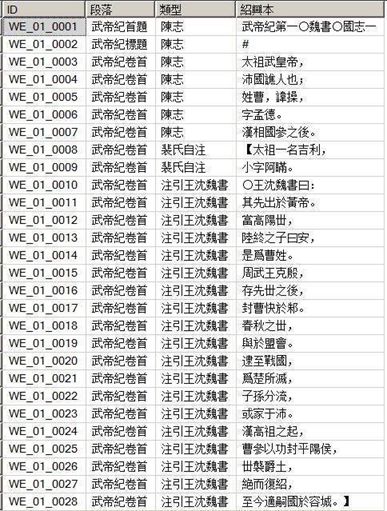
(1)切分語段並導入數據庫
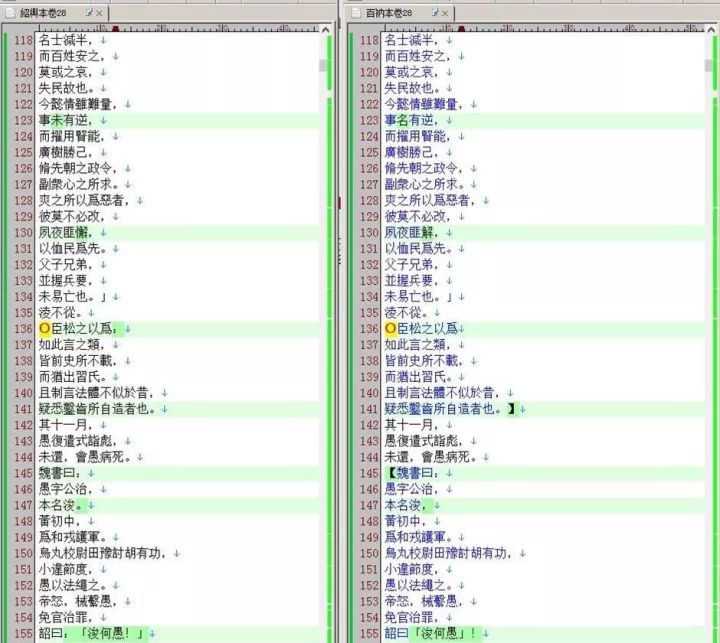
文本處理軟件。工欲善其事,必先利其器。互聯網提供了多款文本比較(compare)軟件,如EmEditor,NotePad+,TextDiff,UltraCompare等等,這些軟件通過語法著色,對兩個文本中相異的字詞句高亮顯示,有助于用戶快速識别。筆者根據自己的習慣,選用EmEditor。


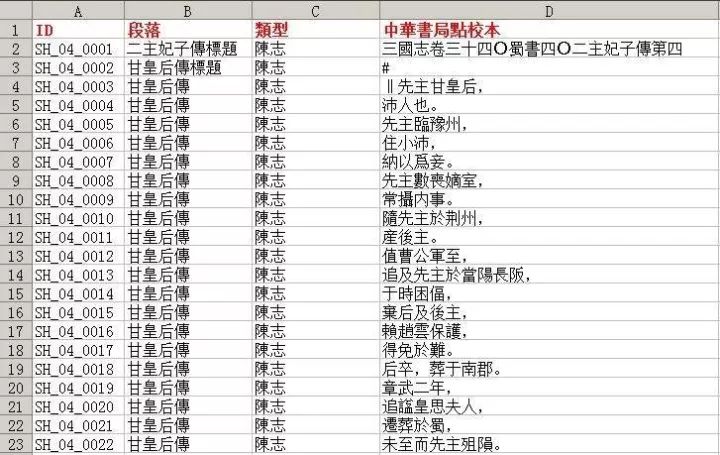
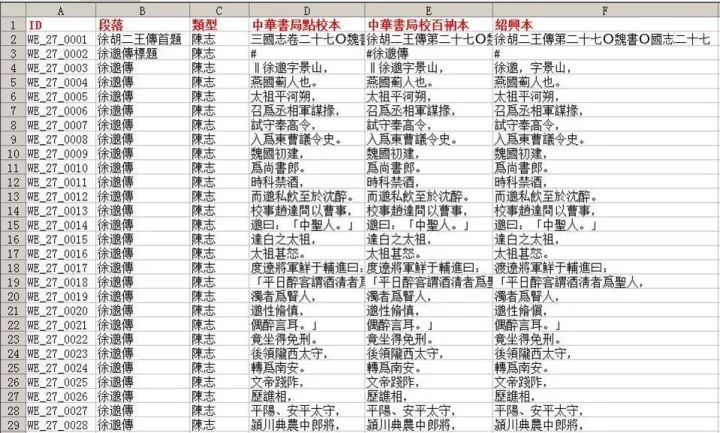
[張森楷校勘記] [nvarchar](max) NULL,
[百衲本校勘記] [nvarchar](max) NULL,
[盧弼集解] [nvarchar](max) NULL,
[點校本校記] [nvarchar](max) NULL,
[復旦本校字記] [nvarchar](max) NULL,
[原修訂長編] [nvarchar](max) NULL,
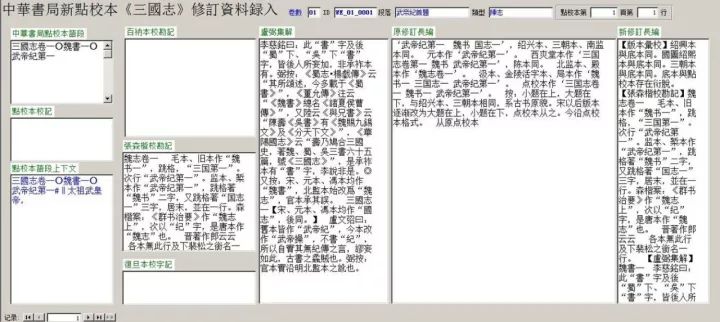
爲了操作更加直觀,也爲了數據庫的安全,我們使用microsoft office的ACCESS鍵接SQL SERVER數據庫的“校勘資料錄入視圖”,構建一個用戶界面友好的操作窗體。


[卷數] [char](2) NULL,
[ID] [char](10) NOT NULL,
[段落] [nvarchar](50) NULL,
[類型] [nvarchar](50) NULL,
[中華書局校百衲本] [nvarchar](100) NULL,
這些屬性便于修訂者快速在書中定位語段,提高效率。爲了增加語段的可讀性,我們又設計了“上下文語境函數”(contexts),動態抓取被修訂語段的前後兩條,共同構成一個相對完整的語境。“語段上下文”不寫入物理表中,只出現在視圖中;視圖關閉,數據就自動從內存中清除。


[國圖紹熙本] [nvarchar](50) NULL,
[日藏紹熙本] [nvarchar](50) NULL,
[咸平本] [nvarchar](50) NULL,
[三朝本] [nvarchar](50) NULL,
[南監本] [nvarchar](50) NULL,
[百衲本校勘記] [nvarchar](max) NULL,
[盧弼集解] [nvarchar](max) NULL,
[點校本校記] [nvarchar](max) NULL,
[復旦本校字記] [nvarchar](max) NULL,
[原修訂長編] [nvarchar](max) NULL,
[處理意見] [nvarchar](max) NULL,
[修訂本校勘記] [nvarchar](max) NULL,
[校記處理] [nvarchar](10) NULL,
[文字處理] [nvarchar](10) NULL,
[標點處理] [nvarchar](10) NULL,
[段落處理] [nvarchar](10) NULL,
[頁] [int] NULL,
[行] [int] NULL,
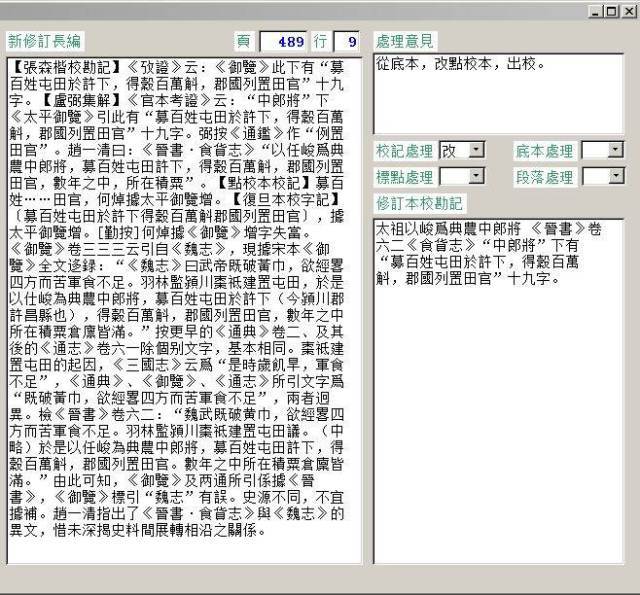
我們最初的計劃是,數據庫架設在網絡服務器上,修訂組成員可以直接在異地實時工作,比文件分發—回收模式要簡單直接。甚至也考慮過採用流水綫作業,把按卷分工的縱向模式改成按模塊分工的橫向方式。但在實際工作中,各方面條件受限,以及工作習慣,我們還是採用了更接近傳統的方式。
全部修訂工作完成後,按照出版社的要求,從數據庫中提取出相應信息,如點校本的卷數、頁、行,修訂長編、處理意見、校勘記,按照卷數和頁、行排序,便于編輯和原點校本對照審核。
二、對古籍整理而言,數字化手段只是輔助工具,合用即可,不必在形式上牽扯過多精力。
三、程序設計是不斷完善的過程,隨著研究工作的深入,需求也會有所變化,程序自然也要隨之修改,研究者無法削足適履去牽就既有的商業程序。因此,爲了更好地服務于古籍整理,研究一點技術非常必要,學習技術的道路也並非高不可攀。
四、數字化技術與古籍整理的質量並無必然聯繫,真正能提高古籍整理水準的是深厚的學養和無畏的獻身精神。
原文